
Prisma ile Modern ORM Yaklaşımı: Tip Güvenliği, Migration ve Performans
Prisma, klasik ORM’lerin yaşattığı zorlukları modern bir bakış açısıyla çözüyor ve geliştirme sürecini hızlandırıyor. Schema-First yaklaşımı sayesinde modelleri ve ilişkileri tek bir dosyada tanımlıyor, buradan tip güvenli bir client üretiyor. Böylece sorgular hem daha okunabilir hale geliyor hem de hatalar derleme aşamasında yakalanabiliyor. PostgreSQL, MySQL, SQLite ve MongoDB desteği ile farklı veritabanlarını tek bir şema üzerinden yönetmek mümkün. Üstelik PostgreSQL ya da MongoDB kullanıyor olsan bile bir tabloya erişme biçimin değişmediği için geliştirici deneyimi (DX) her zaman tutarlı kalıyor. Migration’ların sürümlenmesi, geri alınabilmesi ve verilerin Prisma Studio ile görsel olarak incelenebilmesi de önemli artılar. Özellikle NestJS ve Fastify ekosistemleriyle sorunsuz entegrasyonu da kullanım kolaylığını bir üst seviyeye taşıyor.
Bu yazıda Prisma’yı pratik bir perspektifle ele alacağız. Şema tanımı, migration ve seed süreçleri, minimal veri çekme yöntemleri, ilişkilerde dikkat edilmesi gereken noktalar, sayfalama stratejileri, index ve sorgu optimizasyonu, transaction ve hata yönetimi, test stratejileri ve ortam yapılandırması gibi konulara değineceğiz. Amacım, hem küçük projelerde hızlı bir başlangıç yapabilmeni hem de büyük ölçekli senaryolarda sürdürülebilir bir veri katmanı kurabilmeni sağlayacak kapsamlı bir rehber sunmak.

Prisma’nın Farkı Ne?
Prisma, kendisini “next-gen ORM” olarak konumlandırıyor çünkü geleneksel ORM’lerin çoğunda yaşanan tip güvenliği eksikliğini ve hantallığı ortadan kaldırıyor. Tip güvenli client üretimi sayesinde, veritabanı sorgularını yazarken derleme aşamasında hatalar yakalanıyor ve IDE üzerinde otomatik tamamlama desteğiyle çalışma hızlanıyor. Bu, hem hata oranını düşürüyor hem de geliştiriciye daha güvenilir bir geliştirme deneyimi sunuyor.
Bunun yanı sıra migration yönetimini de kolaylaştırıyor. Şema tabanlı yaklaşım sayesinde veritabanı değişiklikleri tek bir dosyadan yönetilebiliyor, Prisma CLI komutları ile migration’lar sürümlenip kolayca uygulanabiliyor. Bu da özellikle ekiplerin ortak çalıştığı projelerde veritabanı yapısının tutarlı ve izlenebilir kalmasını sağlıyor.
Prisma’nın Temel Yapısı
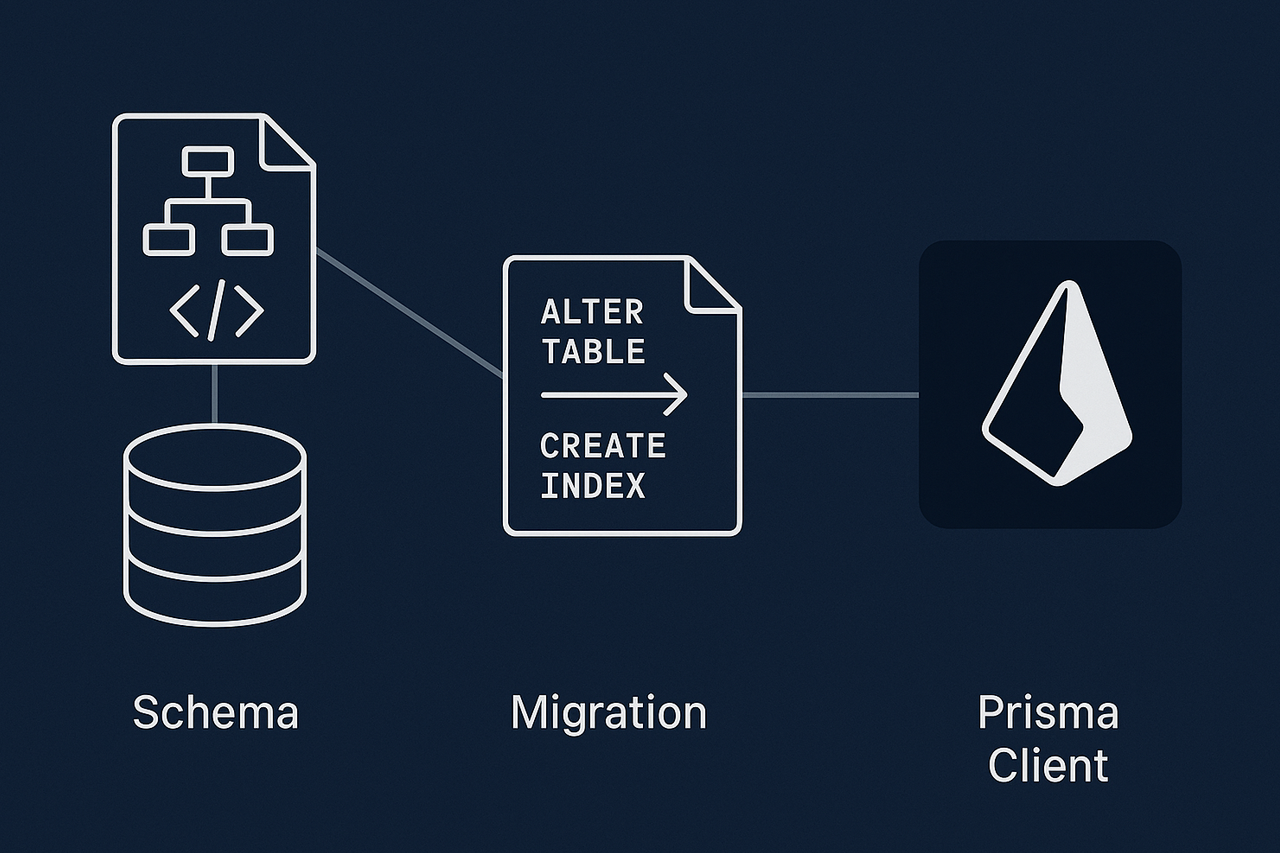
1. Prisma Schema
Prisma’nın kalbi, schema.prisma dosyasıdır. Burada modelleri, alanlarını ve ilişkilerini tanımlarsın. Bu şema, hem veritabanı yapısını tanımlar hem de Prisma Client’ın nasıl üretileceğini belirler. Tek dosya üzerinden tablo oluşturmak, ilişkiler kurmak ve enum tanımlamak mümkündür.
Örnek:
model User {
id String @id @default(cuid())
email String @unique
posts Post[]
}
model Post {
id String @id @default(cuid())
title String
content String?
userId String
user User @relation(fields: [userId], references: [id])
}
Burada User ve Post arasında one-to-many ilişki tanımlanmış olur.
2. Migration Sistemi
Prisma, şemadaki değişikliklerden otomatik olarak SQL migration dosyaları üretir. prisma migrate dev komutu ile local geliştirmede yeni migration’lar oluşturulur ve veritabanına uygulanır.
- Migration’lar sürümlenebilir, yani her değişiklik kayıt altında tutulur.
- İhtiyaç halinde geri alınabilir.
- Ekip çalışmalarında version control (git) ile paylaşılır, böylece veritabanı şeması herkes için tutarlı kalır.
Örnek komutlar:
npx prisma migrate dev --name add_user_model
npx prisma migrate deploy
3. Prisma Client
Şemadan otomatik olarak type-safe bir client üretilir. TypeScript/JavaScript ile veritabanına sorgu yazarken, IntelliSense desteği sayesinde otomatik tamamlama alırsın ve olası hataları compile-time’da yakalarsın.
Örnek kullanım:
const user = await prisma.user.findUnique({
where: { email: "[email protected]" },
include: { posts: true },
});
console.log(user?.posts);
Burada user.posts alanı, şemada tanımlandığı için otomatik olarak tip desteği ile birlikte gelir.
Tip Güvenliği ile Çalışmak

ORM’lerin çoğunda sorgular string tabanlı yazıldığı için hatalar genellikle runtime aşamasında ortaya çıkar. Örneğin yanlış tablo adı veya alan adı kullanırsan uygulama ancak o sorgu çalıştığında hata verir. Bu durum hem debug süresini uzatır hem de production ortamında beklenmedik hatalara yol açabilir.
Prisma ise tip güvenli (type-safe) client üretir. Şemanı baz alarak TypeScript tiplerini oluşturur ve bu sayede hataları compile time aşamasında yakalayabilirsin. Bu yaklaşım, özellikle büyük projelerde güvenilirliği ciddi şekilde artırır. IDE üzerinde otomatik tamamlama desteği sayesinde de hem sorgu yazma hızın artar hem de hata yapma ihtimalin azalır.
Örnek:
// Prisma şemasında "name" alanı yok diyelim
const user = await prisma.user.findUnique({
where: { email: "[email protected]" },
});
console.log(user.name);
Bu kodu yazdığında, TypeScript derleyicisi user modelinde name alanı olmadığı için compile time’da hata verecektir. Yani production’a çıkmadan hata fark edilir.
Ayrıca sorgular tip güvenliği sayesinde daha okunabilir hale gelir:
const posts = await prisma.post.findMany({
select: {
id: true,
title: true,
},
});
Burada posts değişkeninin tipi otomatik olarak şu şekilde çıkarılır:
Array<{
id: string;
title: string;
}>
Böylece ekstra tip tanımı yapmana gerek kalmaz.
Migration ve DB Yönetimi

Prisma’nın güçlü yönlerinden biri de veritabanı migration sürecini geliştirici dostu hale getirmesidir. ORM’lerde çoğu zaman manuel SQL script’leri yazmak veya farklı ortamlar arasında tutarlılığı korumak zor olabilir. Prisma ise schema.prisma dosyasında yapılan değişiklikleri takip eder ve bu değişikliklerden otomatik SQL migration dosyaları üretir.
prisma migrate dev
Lokal geliştirme sırasında kullanılır. Şemada yaptığın her değişiklik sonrası bu komutu çalıştırarak yeni bir migration dosyası oluşturur ve veritabanına uygularsın. Migration dosyaları versiyonlanır ve böylece ekip içi paylaşımda herkes aynı veritabanı yapısını kullanabilir.
npx prisma migrate dev --name add_user_table
prisma migrate deploy
Production ortamında migration’ları güvenli bir şekilde uygulamak için kullanılır. Bu komut yeni migration dosyalarını sırayla veritabanına uygular ve senkronizasyon sağlar. Production veritabanında migrate dev kullanılmaz çünkü development sırasında tabloyu resetleme gibi işlemler yapabilir.
npx prisma migrate deploy
Seed Mekanizması
Migration’larla birlikte seed verileri de yönetilebilir. Örneğin uygulama ilk kurulduğunda bazı başlangıç verilerine (ülke listesi, roller, admin kullanıcı gibi) ihtiyaç duyabilirsin. Prisma’da prisma/seed.ts dosyası oluşturarak başlangıç verilerini ekleyebilirsin.
// prisma/seed.ts
import { prisma } from '../src/prisma';
async function main() {
await prisma.user.create({
data: {
email: "[email protected]",
password: "hashedPassword",
},
});
}
main()
.then(() => console.log("Seeding completed"))
.catch((e) => console.error(e))
.finally(async () => {
await prisma.$disconnect();
});
Ve çalıştırmak için:
npx prisma db seed
Bu mekanizma sayesinde geliştirme, test ve production ortamlarında tutarlı bir başlangıç verisi oluşturmak kolaylaşır.
Performans ve Best Practices

N+1 Query Problemine Çözüm
ORM kullanırken sık görülen sorunlardan biri N+1 query problemidir. Örneğin 10 kullanıcıyı çekip, her biri için ayrı ayrı post sorgusu çalıştırırsan toplamda 11 sorgu çalışmış olur. Bu performansı ciddi şekilde düşürür.
Prisma’da bu problemi çözmek için include veya select kullanabilirsin:
Kötü Örnek – N+1 Query
const users = await prisma.user.findMany();
for (const user of users) {
const posts = await prisma.post.findMany({ where: { userId: user.id } });
}
Bu kod aslında şuna dönüşür:
Önce tüm kullanıcıları çek:
SELECT * FROM "User";
Her bir kullanıcı için ayrı sorgu at:
SELECT * FROM "Post" WHERE "userId" = 'user-1';
SELECT * FROM "Post" WHERE "userId" = 'user-2';
SELECT * FROM "Post" WHERE "userId" = 'user-3';
-- ve böyle devam eder...
Yani 1 (User sorgusu) + N (her user için post sorgusu) → toplam N+1 sorgu.
İyi Örnek – include Kullanımı
const users = await prisma.user.findMany({
include: {
posts: true,
},
});
Bu ise tek seferde JOIN ile çözülür:
SELECT
u."id" as user_id,
u."email" as user_email,
p."id" as post_id,
p."title" as post_title,
p."content" as post_content
FROM "User" u
LEFT JOIN "Post" p ON u."id" = p."userId";
Sonuç JSON’a uygun şekilde Prisma Client tarafından gruplanır. Yani sen users[0].posts diye erişebilirsin, çünkü Prisma mapping işini otomatik yapıyor.
select Kullanımı – Projection
const users = await prisma.user.findMany({
select: {
id: true,
email: true,
posts: {
select: { id: true, title: true },
},
},
});
Bu da SQL seviyesinde sadece gerekli kolonları çeker:
SELECT
u."id" as user_id,
u."email" as user_email,
p."id" as post_id,
p."title" as post_title
FROM "User" u
LEFT JOIN "Post" p ON u."id" = p."userId";
Gereksiz content alanı veya diğer kolonlar çekilmez, böylece network transferi ve bellek kullanımı azalır.
Özetle:
- N+1: çok sayıda ayrı SQL sorgusu → yavaş.
- include / select: tek JOIN + projection → hızlı ve optimize.
Connection Pooling
Serverless ortamda (Vercel, Cloudflare Workers vb.) her istek başına yeni bir veritabanı bağlantısı açmak ciddi performans sorununa ve “too many connections” hatasına yol açar.
Prisma bu sorunu Data Proxy ile çözer. Data Proxy, veritabanı bağlantılarını yöneterek bağlantı havuzu (connection pooling) sağlar. Böylece ölçeklenebilir ve düşük gecikmeli bir yapı kurabilirsin.
Kurulum:
npx prisma generate --data-proxy
Ve .env dosyasında DATABASE_URL yerine proxy URL’si kullanılır.
Indexing ve Query Optimization
Prisma, şemadan otomatik index oluşturmayı destekler. Büyük ölçekli sorgularda index kullanmak query hızını kat kat artırır.
model Post {
id String @id @default(cuid())
title String @db.VarChar(255)
content String?
userId String
@@index([title])
@@index([userId])
}
Prisma’nın ürettiği SQL sorgularını görme yolları

1. DEBUG environment variable (en pratik yöntem)
Prisma Client sorgularını konsolda görmek için:
DEBUG="prisma:query" node index.js
Ya da package.json scriptlerine ekleyebilirsin:
"scripts": {
"dev": "DEBUG=prisma:query ts-node src/main.ts"
}
Örnek çıktı:
prisma:query SELECT "public"."User"."id", "public"."User"."email" FROM "public"."User" WHERE "public"."User"."id" = $1 LIMIT $2 OFFSET $3
Bu sayede Prisma’nın senin TypeScript kodunu nasıl SQL’e çevirdiğini görebilirsin.
2. Query Events (Middleware gibi)
Kod tarafında loglamak için Prisma Client’te event listener ekleyebilirsin:
prisma.$on('query', (e) => {
console.log('Query: ' + e.query);
console.log('Params: ' + e.params);
console.log('Duration: ' + e.duration + 'ms');
});
Bu sayede hangi sorguların ne kadar sürdüğünü runtime’da ölçebilirsin.
3. EXPLAIN / ANALYZE ile Performans Testi
Bir sorguyu Prisma ile ürettikten sonra, aynı SQL’i DB üzerinde çalıştırıp performans analiz edebilirsin.
Örneğin PostgreSQL’de:
EXPLAIN ANALYZE
SELECT * FROM "User" u
LEFT JOIN "Post" p ON u."id" = p."userId";
Bu, sorgunun index kullanıp kullanmadığını, kaç satır taradığını, toplam maliyeti gösterir.
Prisma + Ekosistem

Bu bölüm, Prisma’nın tek başına ORM olmaktan çıkıp nasıl daha geniş bir teknoloji ekosistemiyle uyumlu çalıştığını gösterecek.
NestJS Entegrasyonu (PrismaService)
NestJS ile çalışırken en yaygın yaklaşım, Prisma Client’i tek bir yerde enjekte edilebilir hale getirmektir. Bunun için genellikle bir PrismaService oluşturulur.
// prisma.service.ts
import { Injectable, OnModuleInit, OnModuleDestroy } from '@nestjs/common';
import { PrismaClient } from '@prisma/client';
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit, OnModuleDestroy {
async onModuleInit() {
await this.$connect();
}
async onModuleDestroy() {
await this.$disconnect();
}
}
Daha sonra servislerinde bu PrismaService’i dependency injection ile kullanabilirsin:
@Injectable()
export class UserService {
constructor(private prisma: PrismaService) {}
async findAll() {
return this.prisma.user.findMany();
}
}
Bu yaklaşım ile NestJS üzerinde Prisma’yı her yerde güvenle kullanmanı sağlar.
Next.js API Routes ile Kullanım
Next.js içinde API route’larda Prisma’yı doğrudan kullanabilirsin. Burada önemli nokta, development sırasında Hot Reload yüzünden Prisma Client’in birden fazla instance oluşturmasını engellemektir.
// lib/prisma.ts
import { PrismaClient } from "@prisma/client";
const globalForPrisma = global as unknown as { prisma: PrismaClient };
export const prisma =
globalForPrisma.prisma ||
new PrismaClient({
log: ["query", "error", "warn"],
});
if (process.env.NODE_ENV !== "production") globalForPrisma.prisma = prisma;
Artık herhangi bir API route’ta şöyle kullanabilirsin:
import { prisma } from "@/lib/prisma";
export default async function handler(req, res) {
const users = await prisma.user.findMany();
res.json(users);
}
Böylece Next.js üzerinde hem SSR (server-side rendering) hem de API endpoint’lerinde Prisma sorunsuz çalışır.
Prisma + AI / RAG (Retrieval-Augmented Generation)

Prisma’yı sadece relational veri için değil, AI projelerinde metadata yönetimi için de kullanabilirsin.
- Embeddings → genellikle Pinecone, Weaviate veya PostgreSQL
pgvectorgibi bir vektör DB’de tutulur. - Ama metadata (kullanıcı bilgisi, belge kaynakları, tag’ler, erişim izinleri) için Prisma harika bir çözümdür.
Örnek:
model Document {
id String @id @default(cuid())
title String
content String
source String
createdAt DateTime @default(now())
// vektör DB’deki id referansı
vectorId String
}
Bu model sayesinde:
- Embedding verisi dışarıda durur (Pinecone, Redis, pgvector).
- Prisma ise ilgili metadata’yı type safe şekilde yönetir.
- Kullanıcı bir soru sorduğunda önce Prisma’dan metadata’yı çekip, sonra embedding ID ile vektör DB’de arama yapılabilir.
Böylece Prisma, AI RAG pipeline’ının veri katmanında güvenilir bir rol oynar.
Sonuç
Prisma, ORM kavramını modern bir bakış açısıyla yeniden tanımlıyor. Sağladığı tip güvenliği, güçlü migration yönetimi ve şema-öncelikli yaklaşımıyla geliştirici deneyimini üst seviyeye çıkarıyor. Geleneksel ORM’lerin hantallığını ortadan kaldırırken, günlük geliştirme süreçlerini daha hızlı ve güvenilir hale getiriyor.
Bu nedenle Prisma yalnızca küçük projelerde hızlı prototipleme için değil, büyük ölçekli sistemlerde de güvenli migration’lar, güçlü ilişkisel veri yönetimi ve sürdürülebilir bir veri katmanı oluşturmak için tercih edilebilir. Onu sadece bir “ORM” olarak değil, geliştirici odaklı (developer-first) bir data layer çözümü olarak görmek gerekiyor. Özellikle NestJS ve yapay zekâ entegrasyonlarında sunduğu kolaylıklar, Prisma’yı modern yazılım projelerinde stratejik bir araç haline getiriyor.